ℹ️ 本文基于 Go 1.12 和 1.13 版本,并解释了这两个版本之间 sync/pool.go 的演变。
sync 包提供了一个强大可复用的实例池,可以减少 GC 压力。在使用池(sync.Pool)之前和之后对应用程序进行基准测试非常重要,因为如果不了解它内部的工作原理,可能会影响性能。
池的限制
让我们来看一个基础的例子以了解它如何在一个非常简单的上下文中分配 10k 次:
type Small struct {
a int
}
var pool = sync.Pool{
New: func() interface{} { return new(Small) },
}
//go:noinline
func inc(s *Small) { s.a++ }
func BenchmarkWithoutPool(b *testing.B) {
var s *Small
for i := 0; i < b.N; i++ {
for j := 0; j < 10000; j++ {
s = &Small{ a: 1, }
b.StopTimer(); inc(s); b.StartTimer()
}
}
}
func BenchmarkWithPool(b *testing.B) {
var s *Small
for i := 0; i < b.N; i++ {
for j := 0; j < 10000; j++ {
s = pool.Get().(*Small)
s.a = 1
b.StopTimer(); inc(s); b.StartTimer()
pool.Put(s)
}
}
}
这是上面2个基准测试的结果, 一个没有用 sync.Pool 而另一个使用了:
name time/op alloc/op allocs/op WithoutPool-8 3.02ms ± 1% 160kB ± 0% 10.5kB ± 1% WithPool-8 1.36ms ± 6% 1.05kB ± 0% 3.00 ± 0%
由于循环具有10k次迭代,因此不使用池的基准测试在堆上进行了10k分配,而使用池的基准测试仅进行了3次分配。 这3次分配是由池进行的,但是仅分配了该结构的一个实例。 到目前为止,一切都很好; 使用sync.Pool更快,消耗更少的内存。
但是,在现实世界中,当使用池时,应用程序可能会对堆进行许多新分配。 在这种情况下,当内存增加时,它将触发垃圾回收器。 我们还可以使用runtime.GC()命令在我们的基准测试中强制垃圾收集器模拟此行为:
name time/op alloc/op allocs/op WithoutPool-8 993ms ± 1% 249kB ± 2% 10.9k ± 0% WithPool-8 1.03s ± 4% 10.6MB ± 0% 31.0k ± 0%
现在我们可以看到,使用池的性能较低,而分配的数量和使用的内存则更高。 让我们深入研究一下该包,以了解原因。
内部工作流
深入了解sync/pool.go将向我们展示该包的初始化,它可以回答我们之前的问题:
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
它作为清除池的方法注册到运行时。 同样的方法会被垃圾收集器在其专用文件runtime/mgc.go中触发:
func gcStart(trigger gcTrigger) {
[...]
// clearpools before we start the GC
clearpools()
这就解释了为什么在调用垃圾收集器时性能会降低。 每次垃圾收集器运行时都会清除池。 官方文档也警告我们:
池中存储的任何实例都可能在不通知的情况下被随时自动删除
现在,让我们创建工作流程以了解如何管理池中实例:
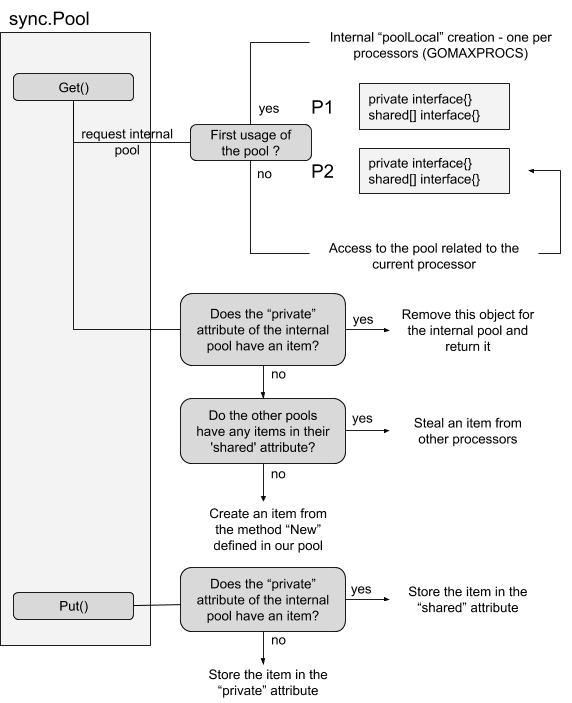
对于我们创建的每个池,go为每个处理器生成一个内部池poolLocal。 此内部池由两个属性组成:私有和共享。 第一个只能由其所有者访问(推入和弹出-因此不需要任何锁),而共享属性可以被任何其他处理器读取,并且需要并发安全。 实际上,该池不是一个简单的本地缓存,它有可能被我们应用程序中的任何线程/ goroutines使用。
Go的1.13版将改善对共享的访问,还将带来一个新的缓存,该缓存应解决与垃圾收集器和清理池有关的问题。
新的无锁池和victim缓存
Go版本1.13带来了一个新的双向链表作为共享池,该列表消除了锁定并改善了共享访问权限。 这是改善缓存的基础。 这是共享访问的新工作流程:

有了这个新的链式池,每个处理器在其队列的开头都可以推入和弹出,而共享访问将从尾部弹出。 队列的头可以通过分配一个与先前结构2倍大小的新的结构来增长,并通过next / prev属性来连接之前的结构。 初始结构的默认大小为8。 这意味着第二个结构将为16,第三个结构将为32,依此类推。
而且,现在不需要锁,并且代码可以依赖于原子操作。
关于新缓存,新策略非常简单。 现在有2组池:活动池(allPools)和归档池(oldPools)。 运行垃圾收集器时,它将使每个池的引用保存在该池内的新属性(victim),然后在清理当前池之前将池的集合复制到归档池中:
// Drop victim caches from all pools.
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// The pools with non-empty primary caches now have non-empty
// victim caches and no pools have primary caches.
oldPools, allPools = allPools, nil
通过这种策略,归功于victim缓存,应用程序现在将有更多一次循环的垃圾收集器来创建/收集带有备份的新实例。 在工作流中,将在请求共享池之后请求victim缓存。
编译自:https://medium.com/a-journey-with-go/go-understand-the-design-of-sync-pool-2dde3024e277